Harnessing the power of BERT embeddings
In this post, I’ll show you how BERT solves a basic text summarization and categorization issue.
About BERT (Bidirectional Encoder Representations from Transformers)
BERT, in a nutshell, is a model that understands how to represent text. You feed it a sequence, and it scans left and right a number of times before producing a vector representation for each word as an output. BERT and other Transformer encoder architectures have been wildly successful on a variety of tasks in NLP (natural language processing).
Structure of BERT
1. The BERT summarizer
It has 2 parts: a BERT encoder and a summarization classifier. In the encoder, we learn the interactions among tokens in our document while in the summarization classifier, we learn the interactions among sentences. To assign each sentence a label , we need to add a token [CLS] before each sentence indicating whether the sentence should be included in the final summary.
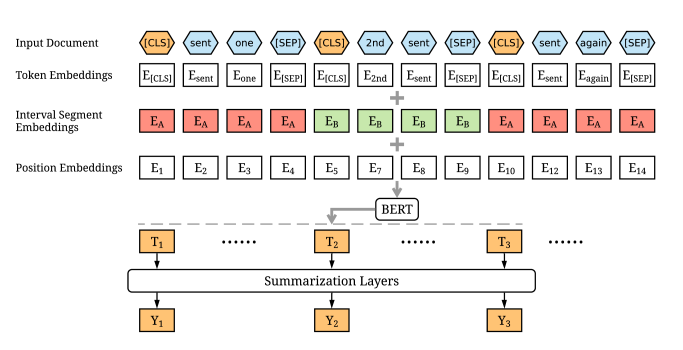
BERT structure for summarization
2. The BERT Classifier
Input — there’s [CLS] token (classification) at the start of each sequence and a special [SEP] token that separates two parts of the input. Output — for classification, we use the output of the first token (the [CLS] token). For more complicated outputs, we can use all the other tokens output.
Comparing BERT with XLNet & GPT-2, for Text Summarization based on performance
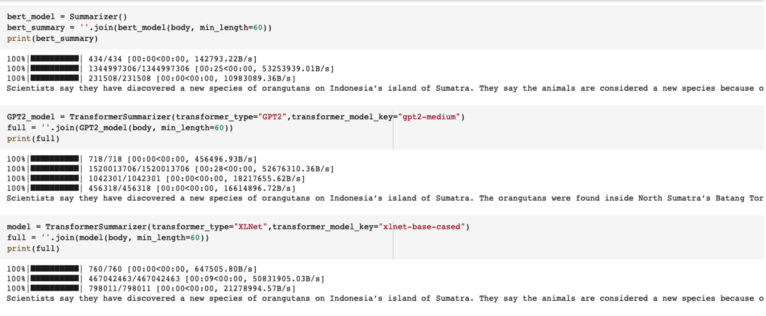
Comparison after installing bert-extractive-summarizer, transformers==2.2.0, spaCy
Results
- Terms of performance — GPT-2-medium is the best
- Terms of time taken — XLNet (11 s) GPT-2 medium (35s) Bert (30s)
- Terms of ease of use — BERT
Step 1: Choosing the BERT Model
There are multiple BERT models available.
Final model used DistilBERT. It is a small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than bert-base-uncased, runs 60% faster while preserving over 95% of BERT’s performances as measured on the GLUE language understanding benchmark.
Step 2: Text classification using BERT
Your mind must be racing with all of the possibilities that BERT has opened up. We can use BERT’s vast knowledge repository in a myriad of contexts for our NLP applications!
1. Let’s Setup!
I have used the AdamW optimizer from tensorflow/models.
|
|
|
|
- Importing and Preprocessing the Dataset
Source: Kaggle
Dataset consistes of consumers’ complaints sent by the CFPB about financial products and services to companies for response to help improve the financial marketplace.
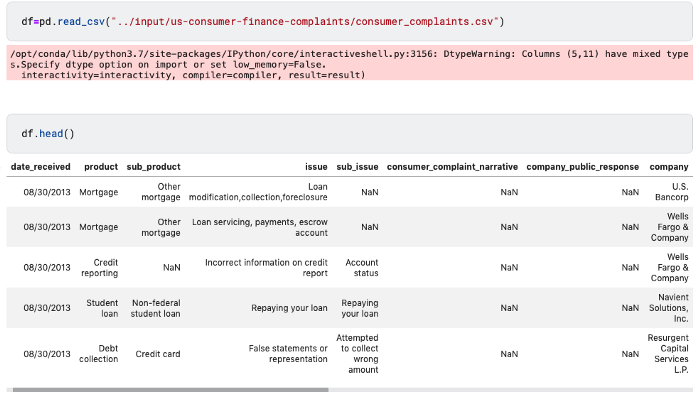
Loading the dataset
2.1. Feature Selection
I have selected the columns that were directly related to resloving the issues and classifying them into the product classes
The output below shows that our dataset has 555,957 rows and 18 columns.
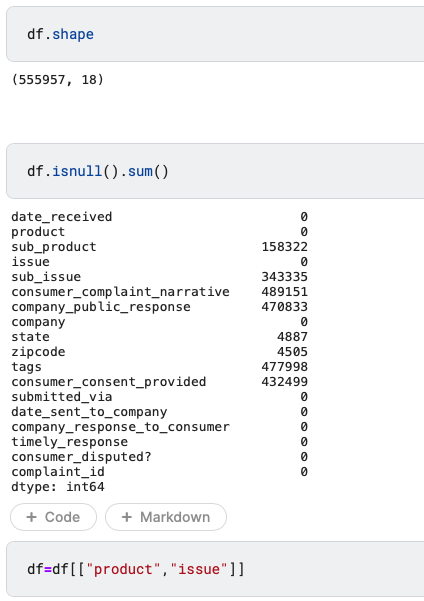
Selected 2 out of 18 features.
Selected 2 out of 18 features.
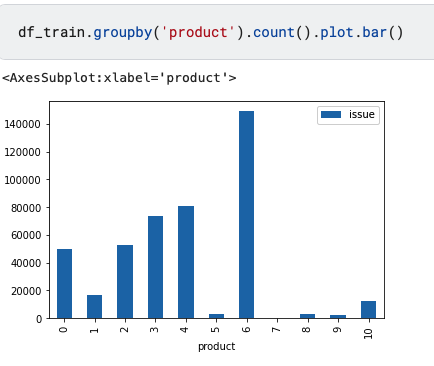
Issues Classified into 10 product categories
2.2. Label encoding
I have label encoded the Product column to convert the text format into label format using LabelEncoder.
LabelEncoder: It allows to assign ordinal levels to categorical data.
fit_transform(y): Fit label encoder and return encoded labels.
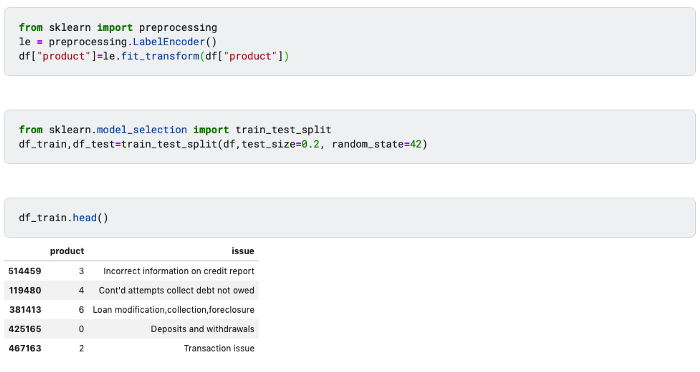
Label Encoding
3. Creating a BERT Tokenizer
-
Text inputs need to be transformed to numeric token ids and arranged in several Tensors before being input to BERT.
-
Tokenization refers to dividing a sentence into individual words. To tokenize our text, we will be using the BERT tokenizer.
Importing the pre-trained model and tokenizer which is specific to BERT
- Create a BERT embedding layer by importing the BERT model from
hub.KerasLayer - Retrieve the BERT vocabulary file in the form a numpy array.
- Set the text to lowercase and pass our vocab_file and do_lower variables to the BertTokenizer object.
- Initialise tokenizer_for_bert.
|
|
|
|
|
|
4. Defining helper function for text preprocessing
- The encode_text function is converting raw text data into encoded text(‘CLS’+token+ ‘SEP’)which is fitted and converted to token
- To create sentences of equal length, I have padded the token_ids, mask_ids, segment_ids to truncate the tokens with the provided batch size.
|
|
- The model will take strings as input, and return appropriately formatted objects which can be passed to BERT.
|
|
|
|
Since this text preprocessor is a TensorFlow model, It can be included in any model directly.
5. Defining the Model
Create a very simple fine-tuned model, with the preprocessing model, the selected BERT model, one Dense and a Dropout layer for regularization. As you can see, there are 3 outputs from the preprocessing that a BERT model would use (input_words_id, input_mask and segment_ids).
Batch size = 40 implies that if the input is >than 40, it will be truncated to 40 tokens and if the input is <40 it will pad it to 40 tokens.
|
|
6. Converting the train text in encoded format
|
|
7. Fine-Tuning the model for text classification
Fine-tuning follows the optimizer set-up from BERT pre-training: It uses the AdamW optimizer.
BERT was originally trained with: the “Adaptive Moments” (Adam). This optimizer minimizes the prediction loss and does regularization by weight decay.
To increase the accuracy, increase the no. of epochs
|
|
Building Pipeline
Flow of Pipeline - Text Summarization using BERT>Text Classification using BERT >Name Entity Recognition using spaCy
For Text Summarization:
Extractive, abstractive, and mixed summarization strategies are most commonly used.
- Extractive strategies — It selects the top N sentences that best represent the article’s important themes.
- Abstractive summaries — It attempts to rephrase the article’s main ideas in new words.
1. Installing bert-extractive-summarizer
2. Installing spaCy : The smallest English language model takes only a moment to download as it’s around 11MB
This tool utilizes the HuggingFace Pytorch transformers library to run extractive summarizations.
This works by first embedding the sentences, then running a clustering algorithm, finding the sentences that are closest to the cluster’s centroids
|
|
|
|
|
|
3. Defining the pipeline function
|
|
Testing the model
Passing input to the trained model to summarize and then classify the text.
|
|
Key Feature Extraction using spaCyNER
About spaCy Named Entity Recognition
spaCy’s Named Entity Recognition (NER ) locates and identifies the named entities present in unstructured text into the standard categories such as person names, locations, organizations, time expressions, quantities, monetary values, percentage, codes etc.

spaCy NER
Accessing the Entity Annotations on the generated summary of the text
|
|
Doc.ents are token spans with their own set of annotations
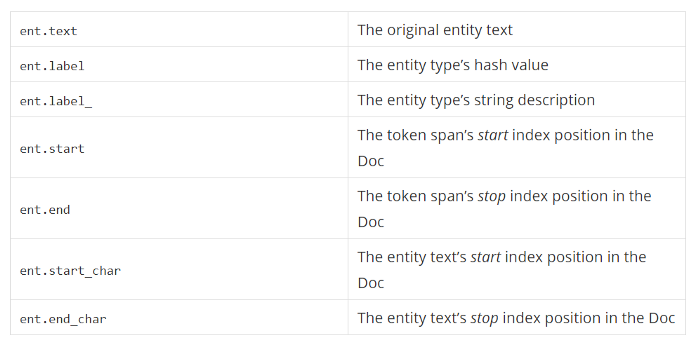
Entity Annotations
Further thoughts
For a much faster approach, I can directly extract the key features by extracting noun phrases from the generated text summary using spaCy.
This would help to get the most common nouns, verbs, adverbs and so on by counting frequency of all the tokens in the text file.
Feel free to play around with spaCy as there is a lot more built-in functionality available. I will be doing this in my next blog. Stay connected!