Speed up the development with advanced pair programming: GitHub Copilot
Something Microsoft couldn’t get their hands off of, and you probably won’t be able to either!
Hello technophiles, Welcome to my blog! Read along to know political, technical, and public understandings and viewpoints on the great magical AI algorithm launched this week.

“Anyone who puts in money at OpenAI can only expect returns 100 times their investment”
Let’s talk about Microsoft investment of $1 billion in OpenAI
OpenAI, a San Francisco-based research lab founded by Silicon Valley luminaries, including Elon Musk and Sam Altman, that’s dedicated to creating artificial general intelligence (AGI). In order to restrain the greed of investors, OpenAI operates as a capped-profit entity.

The CEO moment: Sam Altman and Satya Nadella
The investment has made Microsoft the “exclusive” provider of cloud computing services to OpenAI, and the two companies will work together to develop new technologies, to explore artificial intelligence’s magic formula.
GPT -3 and capitalism; Could there be a boom followed by a bust?
We’ve noticed that politicians are lured by the enormous tax revenue generated by CEOs, as well as the popularity gained by paying their voters’ wages (UBI). Politicians believe Sam is no different from any other capitalist attempting to persuade the government to accept an oligarchy. Sam Altman suggested wealth taxation strategies, mentioning -
“The American Equity Fund would be capitalised by taxing companies above a certain valuation 2.5% of their market value each year, payable in shares transferred to the fund, and by taxing 2.5% of the value of all privately-held land, payable in dollars.”
To this, Daron Acemoglu, an economist at MIT and Richard Miller, founder of tech consultancy firm Miller-Klein Associates, told CNBC -
“Altman’s post feels muddled and the model is unfettered capitalism.” “There is an incredible mistaken optimism of what AI is capable of doing.”
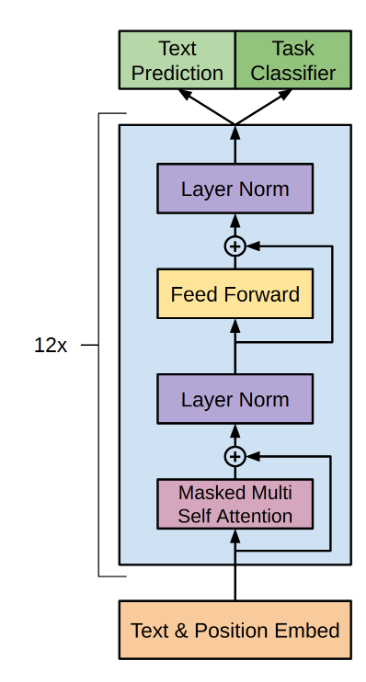
Recipe to Copilot:Architecture of GPT-3
GitHub Copilot has been trained on billions of lines of publicly available code. While we amusingly explore the consequences, the processing behind it is ultimately based on GPT-3, so let’s see how it works.
To understand the architecture of Transformer based Language Model better, I want you to follow the questions that lead to the following explanations -
How does the model take input and what are the inputs and outputs of GPT?
1. Defining Input and output
Input sequence — get the next word.
Input - For GPT-3, the input is a sequence of 2048 words (a.k.a tokens).
Output - Once we give the input, we get the guess for the next word as the output.
The GPT output is not just a single guess, it’s a sequence (length 2048) of guesses (a probability for each likely word). Keep repeating to get long generated texts.
Example -
|
|
Machine does not understand words, so how do we turn words into vectors?
2. Byte Pair Encoding
GPT-3 uses byte-level Byte Pair Encoding (BPE) tokenization for efficiency. This indicates that the vocabulary’s “words” aren’t whole words, but rather groups of characters (for byte-level BPE, bytes) that appear frequently in text.
- Step 1: Keep a vocabulary of all words, which will allows us to give each word a value
- Step 2: Turn each word into a one-hot encoding vector.
GPT has a vocabulary of 50257 words, we do this for every word in the sequence which results in a 2048 x 50257 matrix of ones and zeroes.
The matrix generated is mostly filled with zeros, which is a lot of wasted space. How will we solve this?
3. Embedding
GPT uses 12288 dimensions.
Dimensions are basically properties(king/queen) of the data, hence for text embedding we must know exactly which word is meant to find relations between them according to the features(he/she) as shown in figure. Dimensions are basically properties(king/queen) of the data, hence for text embedding we must know exactly which word is meant to find relations between them according to the features(he/she) as shown in figure. This helps to store the information of the word’s meaning to a smaller dimensional space, by value for each property. This helps to store the information of the word’s meaning to a smaller dimensional space, by value for each property.
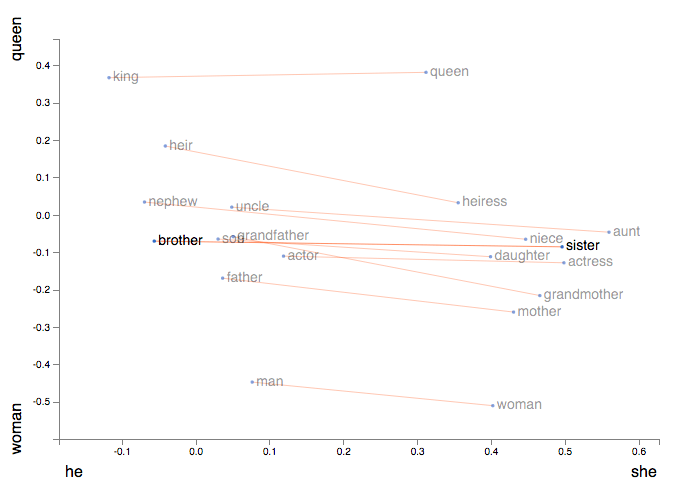
Vector representation of 2D embedding.
We multiply the 2048 x 50257 sequence-encodings matrix with the 50257 x 12288 embedding-weights matrix (learned) and end up with a 2048 x 12288 sequence-embeddings matrix.
For output in the sequence, how to predict which input word to focus on and how much?
4. Attention
What attention does -
It maps a query and a set of key-value pairs to an output in the form of vectors. The output is computed as a weighted sum of the values.
Multi-head attention in GPT -
GPT model presented by the authors, they use multi-head attention. Which means is that the attention process is repeated many times (96x in GPT-3), each with a different learned query, key, value projection weights.
Sparse attention in GPT-3 -
Transformers are powerful sequence models, it gets impractical to compute a single attention matrix, for very large inputs. hence in sparse attention patterns, each output position only computes weightings from a subset of input positions.
It gives the following benefits -
It gives a lower loss than full attention, in addition to being significantly faster for the re-computation of attention matrices to save memory.
Sparse attention is algorithmic improvement of the attention mechanism to extract patterns from sequences 30x longer than possible previously.
5. Feed Forward
Its a simple multi-layer-perceptron with 1 hidden layer
Working of Feed Forward: It takes input, multiply with learned weights, add learned bias, applies to ReLU(activation function) and gets result.
6. Add & Norm
After both the Multi-Head attention and the Feed Forward blocks, the input of the block is added to it’s output, and the result is normalized.
After the input is processed into a huge matrix, it contains information about the next predicted word. How do we extract this information?
7. Decoding
To obtain information, the mapping done in the embeddings section is reversed to transform our output 12288-vector embedding back into a 50257-word-encoding.
After a quick softmax, we can then treat the resulting values as probabilities for each word.
GitHub Copilot Recitation
The GitHub Copilot is a tool which is designed to work with a programmer rather than independently (i.e pair programmer). This is a huge achievement. Kudos to the GitHub Copilot team!
Copilot is going to be an indispensable part of the programmer tool belt similar to IDE autocomplete for many people.
It guesses the exact code we want to write about one in ten times, and the rest of the time it suggests something rather good, or completely off. But when it guesses right, it feels like it’s reading our mind!
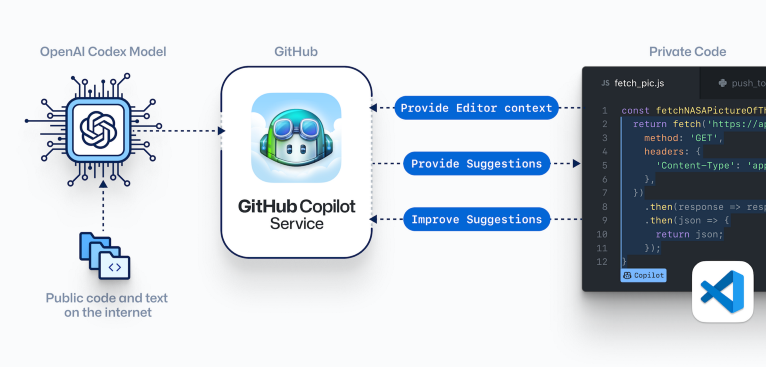
Working of the GitHub Copilot as a VS Code extension: The editor plugin sends comments and code to the GitHub Copilot service, then synthesises and offers ideas to the user using OpenAI Codex.
Is GitHub Copilot architecture, language agnostic?
According to GitHub, Copilot supports a wide range of frameworks and languages, although as we see the technical preview, it is mainly focused with dynamic languages like Python, JavaScript, TypeScript, Ruby, and Go.
It uses the same GPT-3 architecture for different languages as it was trained using huge corpus of GitHub’s public source codes as a data source for dataset, which contains multiple languages.
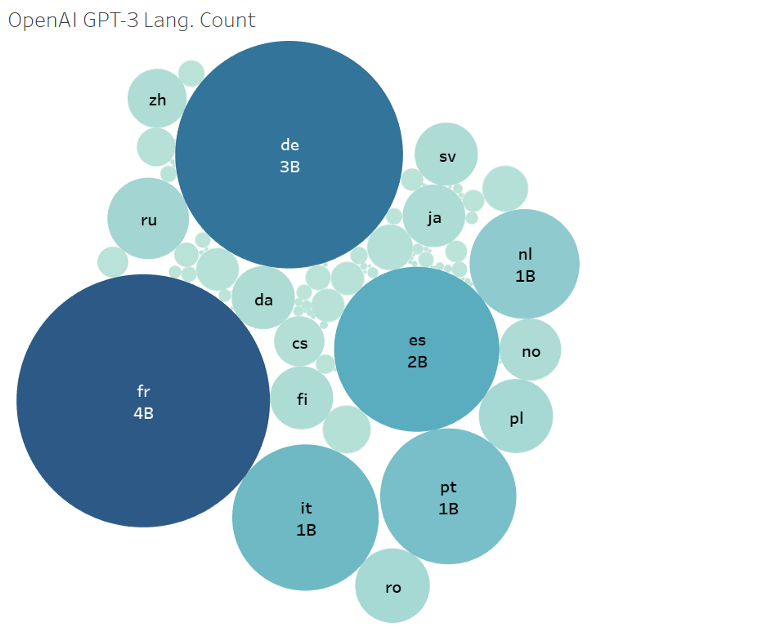
Representing bubble graph: GPT-3 was trained using multiple language datasets.
This speciality can remove barriers to entry. It can help with learning new languages, and for folks working on polyglot codebases.
Hands-on Demo of GitHub Copilot and it’s impact on domain specific edges
In the field of development
Github Copilot is really great for those developers who properly document and comment their code. According to me, this allow programmers to become more productive, which will increase demand for the skills.
1. API development Domain
- It is capable of writing a Javscript code and It can also write codes for the development of complete API and Python scripts.
- It can be used to write different algorithms such as binary search, binary sort, merge sort, etc.
- It is useful in repetitive low signal to noise ratio languages like React or Java, but is less appealing if you’re writing code in Clojure environment.
The best thing about Github Copilot here is that it automatically produces the best codes keeping in mind the Time Complexity.
2. Web Development Domain
- Github Copilot does a pretty good job while predicting the React codes.
- When we tried to predict React+Typescript the Github Copilot was not able to perform efficient prediction, it went on to to predict the most common use case.
- Redux requires a lot of Boilerplate functions. While trying Github Copilot on Redux, it often wasn’t sure about the relevancy. It doesn’t knows what is relevant and what is not.
3. App Development Domain
- While working with flutter the basic boilerplates codes are easy to predict for Github Copilot.
- As the code starts to get complicated and we need to create API with a query and response, it fails to predict the complete code accurately.
- Platforms such as Geeks For Geeks and LeetCode don’t have to spend time and capital in hiring people to write codes for teaching. This will result in more effecting teaching and learning for the freshers.
According to the tests by Krish Naik to write a function to find the smallest five elements in an array sorted in an ascending order and the Github; Copilot took only 2 seconds to create the function.
4. Data Science for Machine Learning pipelines and Deep Learning
- It is good at basic data preprocessing and exploratory data analysis.
- It is able to write a function for a basic neural network.
- It struggles to write the basic machine learning model code.
- There are multiple times when we pass the comment , it is not able to define a specific Machine Learning model.
- Every time we asked GitHub Copilot to write the code for basic machine learning, often it gave a basic code structure of what machine learning code should look like as an output.
- The Github Copilot isn’t as great for Data Science as it is for writing DSA and Python scripts. When it comes to writing codes which require some serious thinking like writing complicated deep neural networks then Github Copilot fails to stand up to the expectations.
Opinions on Most trending discussions
Drawbacks observed
- The code that Copilot suggests is not tested. The code will almost always fail to compile or run.
- The Github Copilot only stores a limited amount of context. Any source file longer than 100 lines is clipped, and the tool only looks at the context that comes before it. Hence, while writing long codes it will be really disappointing to expect continuous performance from the tool.
- GitHub Copilot has been trained on billions of lines of publicly available code, it is extremely accurate. As a result, the proposed code and the code that is informed by it may have a direct link.
Further thoughts and ideas
Generating short summary at the end of generated code for better understanding
Auto-code completion can make it difficult for novices to comprehend the code created by GitHub Copilot and for big codes written by AI, it takes more time to understand.
I’m wondering whether we might make a modified version that creates a brief written summary at the conclusion of the generated code using sequence by sequence codes as input.
Taking input functions in the form of Speech for easy accessibility
We can do this by performing the task of speech-to-text conversion using state-of-the-art ASR models such as Wav2Vec2.
Although, prior to this step we will need to train the model on a large dataset which contains technical conversation about different programming languages and computer science related domains.

Thank you readers for staying with me until the end; Did my blog motivated you to join the GitHub Copilot waiting list? Please let me know how it works out for you in the comments!