Auto-code generation using GPT-2
About GPT-2
GPT-2 stands for “Generative Predictive Transformer”. It is an open-source model trained on an over 1.5 Billion parameters for generating the next sequence of text, for a give sequence.
The GPT-2 has a remarkable and amazing competence to generate texts, much beyond the expectations of conventional language models.
“Too dangerous to be released.”
A phrase published the press statement by OpenAI to accompany their announcement of the release of their GPT-2 language model in February 2019.

The threat of AI-driven misinformation has become a huge issue that remains unresolved in today’s post-factual information ecosystem, especially with the recent release of the more powerful GPT-3.
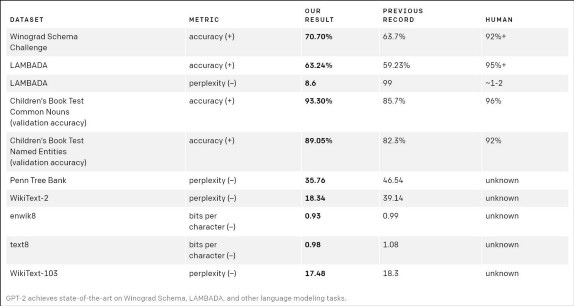
Performance of GPT on different datasets
“Today, the United Nations has called for the immediate withdrawal of all nuclear weapons from the world.”
The sentence you just read was neither written by me, nor was it written by the editor. This sentence was written by GPT-2.
GPT-2 is a 1.5-bit transformer-based language model, trained in a database of 8 million web pages. It was trained to simply predict the next word in 40GB of Internet text. Due to some issues a very small model for researchers was released to experiment with.
Working mechanism of GPT-2
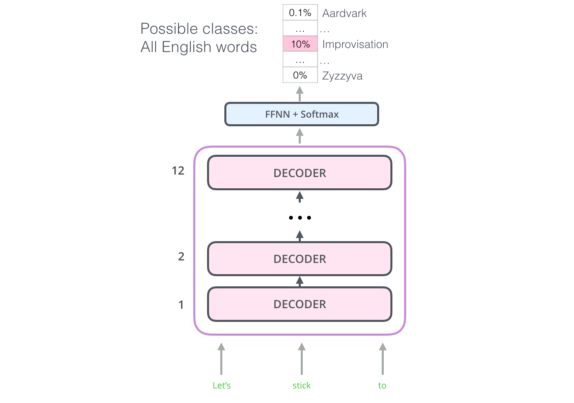
Working of GPT-2
-
Generative: This means that model was trained to predict the next token in a given sequence of tokens. The model is given a lot of raw text and then it is asked to generate more text using the statistical features which ofcourse involves implementation of different layers and mechanism such as RNN-LSTM and Attention mechanism.
-
Pre-trained: OpenAI trained a large and a powerful language transformer model to use it for tasks like summarization, neural machine translation, etc. Now, the model was trained on 40 GB of text, known as WebText.
Transformer Architecture
- Transformer: The GPT-2 is build using layers of decoder transformer blocks.

The text in blue is given as an input and the text in red is the predicted output
The GPT-2 architecture is based on the concepts of the transformers.
The mechanism on which GPT-2 works involves transformer based encoder decoder architecture to learn the input and output dependencies.
To generate the next output in a given sequence the model need to have the previously generated data as an input.
-
The GPT-2 has a great ability to adapt to the context of the text and thus generates realistic and coherent output.
-
The model works by adding each token to the sequence of inputs as it is created. In the next step, that new sequence becomes the model’s input. This is an idea called “auto-regression”. This is one of the ideas that made RNNs unreasonably effective.
What is the meaning of automatic code generation?
The automatic code generation is basically involves the completion of a sequeunce of codes based upon the previous inputs and past habits of the user.
-
Many commercial platforms such as TabNine and Kite are already available in the market for this task. These both use GPT-2 to predict the next sequence of codes based upon the previous inputs provided by the users.
-
Here is a short video which demonstrates the amazing capabilities of an automatics code generation process:
Steps to fine-tune GPT-2 for code generation
1. Cloning the required repositories
-
Here, we are cloning the auto_coding repository which contains code and scripts to fine tune the GPT-2 model for automatic code generation.
-
We need to provide the training examples in the form of scripts (Examples: Python, C, C++, Java, and Javascript).
-
For fine-tuning our GPT-2 model we have used scripts from scikit-learn examples.
|
|
2. Downloading the required scripts
Now, we are downloading the convert.py script.
This script contains the code to convert our examples into the training data in a format expected by our model.
|
|
3. Navigating to the required directing
Here, we are executing the convert.py script with segment length as 256, strides of 10, and development size of 10%.
The 90% of the data will be used for training and the remaining 10% will be used for testing our model.
|
|
4. Executing the training scripts and selecting the model as distilgpt2
We have different versions of models available for fine-tuning. Here, distilgpt2 is selected to be fine-tuned. If one has enough computing resources and huge dataset then they may go for version with larger number of parameters.
|
|
5. The model is now trained. Let’s check out the model
After the training get’s completed we need to execute interact.py script. This script will run the model for testing purpose. The input needs to be provided and the model will predict the sequence.
|
|
How this use case is helping tech professionals?
-This solution is already being used in the industry. It allows developers to code faster with 47% less keystrokes. This helps developers to become more productive.
-
Also, if a block of code is already written earlier then the user just need to make few strokes of identical words and the user will get an automatically completed block of codes.
-
According, to some of the reviews, this has helped developers reduce a chunk of time, since they are writing just 70% to 80% codes and the rest 20% to 30% of the code is automatically generated.
-
With all these advantages, the industry is also saving a significant amount of time.
Limitations of GPT-2
-
GPT-2 cannot be used handle complex and long language formations.
-
If someone wants to generate a sequence of text related to a particular domain such as literature, finance, or medicine, then it won’t be able to perform well.
-
There are certain limitations in terms of computing resources. To train such a huge model with billions of parameter we require very expensive computing resources to train so that the model can perform better.
Writer’s perespective on GPT architecture
-
The GPT is no doubt an amazing invention in the field of Natural Language Processing but it’s capabilities are still unknown since the complete pre-trained model was never released by OpenAI because of some serious threats.
-
For performing this task on automatic code generation I used distil-GPT2 because of it’s small size and relatively less expensive model fine-tuning. We limited the sequence generation size to 15 for more effective and crisp prediction.
-
If one has thought of using GPT-2 model with higher number of parameters then the size of sequence can be increased accordingly, keeping the computing resources in mind.

Here is a tweet from VP of AI at Facebook
I’m quite aware of the additional risks, such as the possibility of GPT-3’s human-like text generation capacity being used for phishing, scamming, spamming, distributing false news, or other fraudulent actions. Hence, one should use such models keeping ethics in mind.
We should use artificial intelligence to make our lives better and not by doing anytype of criminal activities.
Conclusion
Congrats for making it all the way to the end of this blog! Thank you very much for taking the time to read this. I hope it was useful in getting you up and going.
Did you like GPT-2’s superpowers? Please let me know in the comments section where all thoughts and insights are eagerly appreciated.